How Technology and Reliable Data Can Help Tackle Water Pollution October 7th, 2019
Via World Economic Forum, a look at how data and technology can help tackle the globe’s water pollution challenge:
Humans have wrestled with water quality for thousands of years, as far back as the 4th and 5th centuries BC when Hippocrates, the father of modern medicine, linked impure water to disease and invented one of the earliest water filters. Today, the challenge is sizeable, creating existential threats to biodiversity and multiple human communities, as well as threatening economic progress and sustainability of human lives.
Increasing the economic and human cost of toxic water-bodies
To set up effective interventions to clean rivers, decision-makers must be provided with reliable, representative and comprehensive data collected at high frequency in a disaggregated manner. The traditional approach to water quality monitoring is slow, tedious, expensive and prone to human error; it only allows for the testing of a limited number of samples owing to a lack of infrastructure and resources. Data is often only available in tabular formats with little or no metadata to support it. As such, data quality and integrity are low.
Using automated, geotagged, time-stamped, real-time sensors to gather data in a non-stationary manner, researchers in our team at the Tata Centre for Development at UChicago have been able to pinpoint pollution hotspots in rivers and identify the spread of pollution locally. Such high-resolution mapping of river water quality over space and time is gaining traction as a tool to support regulatory compliance decision-making, as an early warning indicator for ecological degradation, and as a reliable system to assess the efficacy of sanitation interventions. Creating data visualizations to ease understanding and making data available through an open-access digital platform has built trust among all stakeholders.
Pictorial representation of a non-stationary, real-time sensor system with cloud-based data storage and digital dissemination capabilities
How machine learning can produce insights
Beyond collecting and representing data in easy formats, there is a possibility to use machine learning models on such high-resolution data to predict water quality. There are no real-time sensors available for certain crucial parameters estimating the organic content in the water, such as biochemical oxygen demand (BOD), and it can take up to five days to get results for these in a laboratory. These parameters can potentially be predicted in real-time from others whose values are available instantaneously. Once fully developed and validated, such machine learning models could predict values for intermediary values in time and space.
Real-time application of a neural network to easily available parameters to predict other water quality indicators
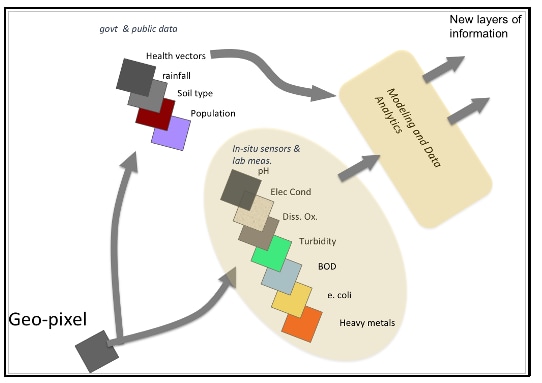
Furthermore, adding other layers of data, such as the rainfall pattern, local temperatures, industries situated nearby and agricultural land details, could enrich the statistical analysis of the dataset. The new, imaginary geopixel, as Professor Supratik Guha from the Pritzker School of Molecular Engineering calls it, has vertical layers of information for each GPS (global positioning system) location. Together they can provide a holistic picture of water quality in that location and changing trends.
The new imaginary geopixel, as Professor Supratik Guha from the Pritzker School of Molecular Engineering calls it, has vertical layers of information for each geotagged location
Technology and public policy
In broad terms, machine learning can help policy-makers with estimation and prediction problems. Traditionally, water pollution measurement has always been about estimation – through sample collection and lab tests. With our technology, we are increasing the scope and frequency of such estimation enormously – but we are also going further. With our machine learning models, we are trying to build predictive models that would completely change the scenario of water pollution data. Moreover, our expanded estimation and prediction machine learning tools will not just deliver new data and methods but may allow us to focus on new questions and policy problems. At a macro level, we aim to go beyond this project and hope to bring a culture of machine learning into Indian Public Policy.
Data disclosure and public policy
Access to information has been an important part of the environmental debate since the beginning of the climate change movement. The notion that “information increases the effectiveness of participation” has been widely accepted in economics and other social science literature. While the availability of reliable data is the most important step towards efficient regulation, making the process transparent and disclosing data to the public brings many additional advantages. Such disclosure creates competition among industries on environmental performance. It can also lead to public pressure from civil society groups, as well as the general public, investors and peer industrial plants, and nudge polluters towards better behaviour.
,
ABOUT
New technical innovations such as location-tracking devices, GPS and satellite communications, remote sensors, laser-imaging technologies, light detection and ranging” (LIDAR) sensing, high-resolution satellite imagery, digital mapping, advanced statistical analytical software and even biotechnology and synthetic biology are revolutionizing conservation in two key ways: first, by revealing the state of our world in unprecedented detail; and, second, by making available more data to more people in more places. The mission of this blog is to track these technical innovations that may give conservation the chance – for the first time – to keep up with, and even get ahead of, the planet’s most intractable environmental challenges. It will also examine the unintended consequences and moral hazards that the use of these new tools may cause.Read More